
PolarQuant Models
Collection
Optimal Gaussian quantization via Hadamard rotation. Beats torchao INT4 on PPL. arXiv: 2603.7424577 • 25 items • Updated • 2
Naming notice (2026-04-10). The "PolarQuant" technique used in this model is being rebranded to HLWQ (Hadamard-Lloyd Weight Quantization). The change is only the name; the algorithm and the weights in this repository are unchanged.
The rebrand resolves a name collision with an unrelated, earlier KV cache quantization method also named PolarQuant (Han et al., arXiv:2502.02617, 2025). HLWQ addresses weight quantization with a deterministic Walsh-Hadamard rotation and Lloyd-Max scalar codebook; Han et al.'s PolarQuant addresses KV cache quantization with a random polar rotation. The two methods are technically distinct.
Existing loaders that load this repository by ID continue to work without changes. Future model uploads will use the HLWQ name.
Reference paper for this technique: arXiv:2603.29078 (v2 in preparation; v1 still uses the old name).
PQ5+INT4 weights for consumer GPU inference.
30B-A3B MoE | MLA attention | MIT license | 22.2 tok/s
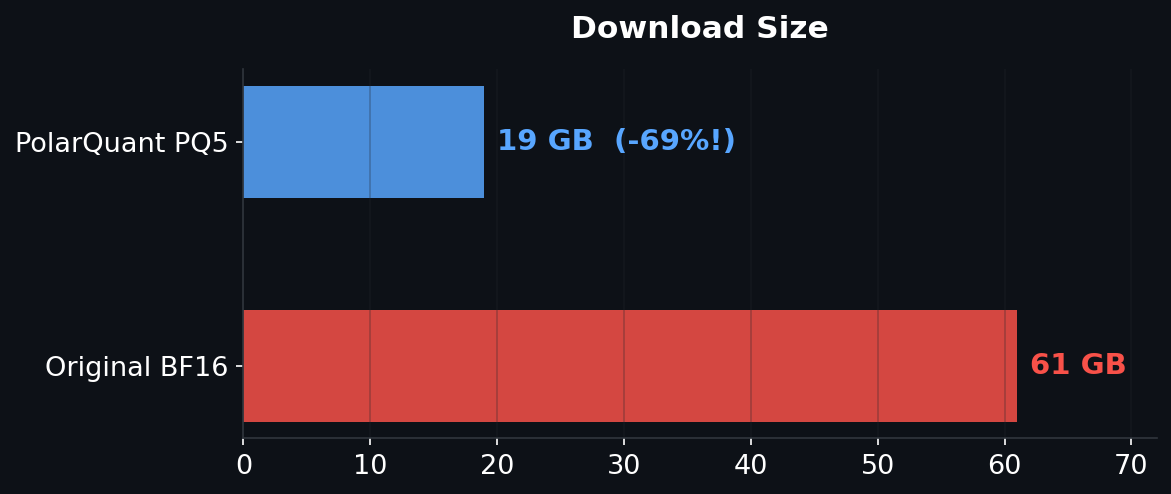
61 GB → 19 GB (-69%) | cos_sim >0.998 | 6,265 layers quantized

| Component | Layers | Original (est.) | PQ5 Packed |
|---|---|---|---|
| nn.Linear (INT4) | 377 | ~8 GB | 1.8 GB |
| MoE Experts | 5,888 slices | ~50 GB | 15 GB |
| Norms/Embed | — | ~3 GB | 3 GB (kept) |
| Total | 6,265 | 61 GB (measured) | 19 GB (-69%) |
Per-component "Original" sizes are estimated breakdowns — only the total 61 GB was directly measured from the full BF16 download.
| Metric | Value |
|---|---|
| VRAM | 58.0 GB |
| Speed | 22.2 tok/s |
| Peak VRAM | 58.3 GB |
| Polar Codes | 19.0 GB (bit-packed) |
| Quantized | 377 linear + 5,888 experts |
| GPU | VRAM | Status |
|---|---|---|
| A100 (80 GB) | 80 GB | Fits fully (58 GB used) |
| RTX PRO 6000 (96 GB) | 96 GB | Fits fully |
| A100 (40 GB) | 40 GB | Expert offloading needed |
| RTX 4090 (24 GB) | 24 GB | Expert offloading needed |
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load PQ5 codes and dequant
# See setup instructions at github.com/caiovicentino/polarengine-vllm
# Or use vLLM for serving:
# vllm serve zai-org/GLM-4.7-Flash --tool-call-parser glm47
@article{polarquant2026,
title={PolarQuant: Hadamard-Rotated Lloyd-Max Quantization},
author={Vicentino, Caio},
journal={arXiv preprint arXiv:2603.29078},
year={2026}
}
61 GB → 19 GB with cos_sim >0.998. MIT license. Quantized with PolarQuant.
Base model
zai-org/GLM-4.7-Flash