
HLWQ Unified (Weights Q5 + KV Cache Q3)
Collection
Full-stack HLWQ: Q5 weights + torchao INT4 + Q3 KV cache · formerly PolarQuant Unified • 17 items • Updated • 2
30B hybrid Mamba + MoE model running at 7.6 GB VRAM, 15 tok/s, correct output on RTX 4090.
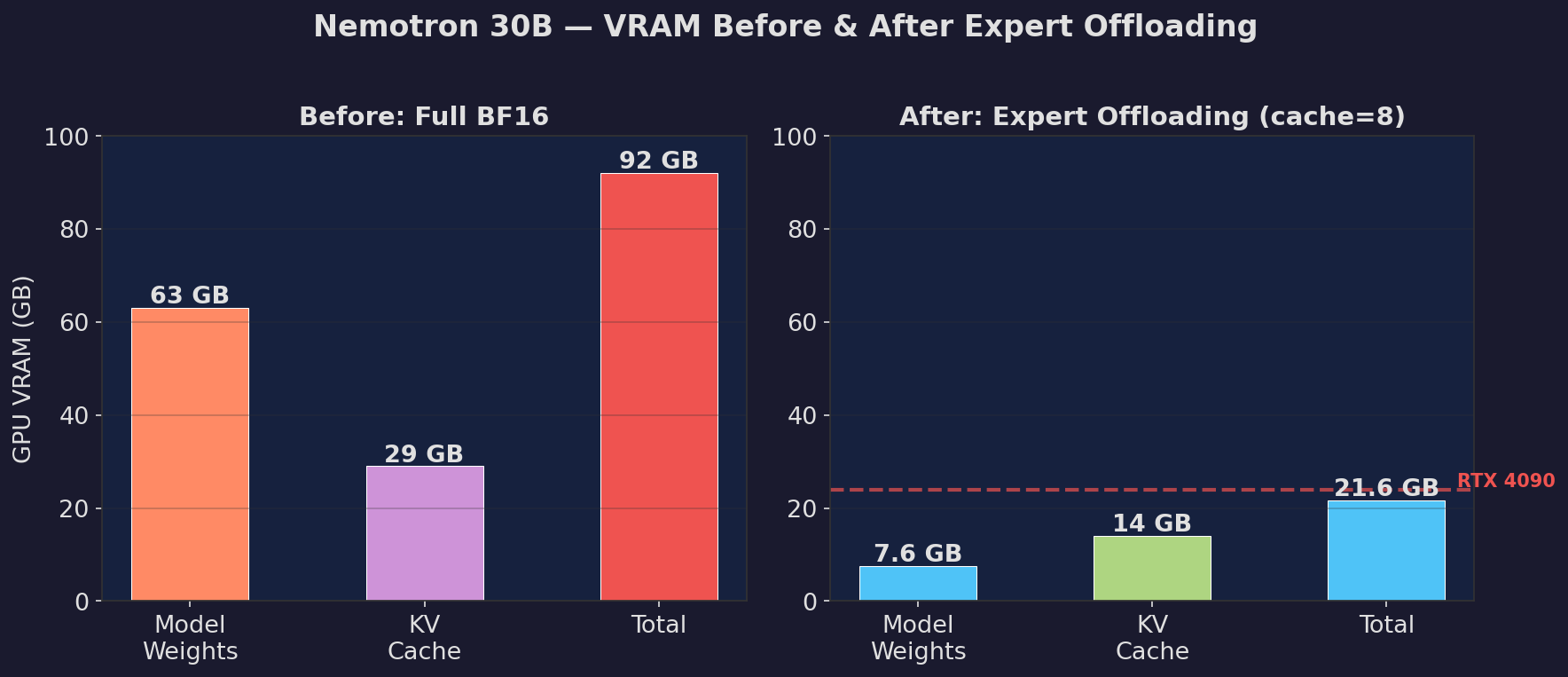
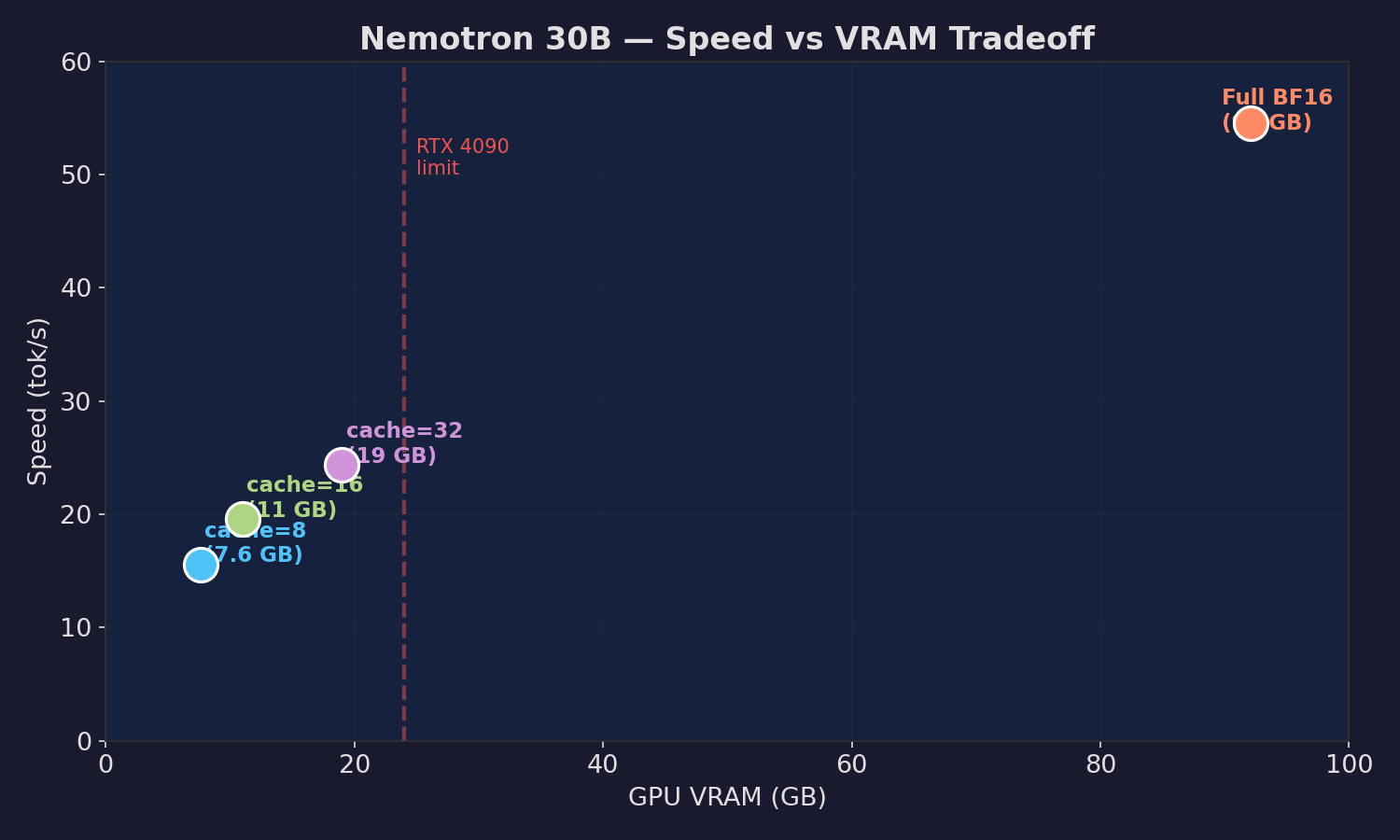
| Config | tok/s | Model VRAM | Quality |
|---|---|---|---|
| Full BF16 (baseline) | 54.5 | 92 GB | Perfect |
| Expert cache=8 (LFRU) | 16.4 | 7.6 GB | Perfect |
| Expert cache=8 (LRU) | 14.6-16.9 | 7.6 GB | Perfect |
| Expert cache=16 | 19.6 | 11 GB | Perfect |
| Expert cache=32 | 24.4 | 19 GB | Perfect |
The fastest and most reliable path uses the BF16 base model with the vLLM expert offload fork. The MoE experts live in CPU pinned memory with an LFRU cache on GPU.
Requirements:
# The vLLM expert offload PR #37190 is OPEN (not yet merged).
# Install the working fork until it lands in mainline:
pip install git+https://github.com/caiovicentino/vllm-expert-offload.git
from vllm import LLM, SamplingParams
llm = LLM(
model='nvidia/Nemotron-Cascade-2-30B-A3B',
trust_remote_code=True,
dtype='bfloat16',
max_model_len=4096,
enforce_eager=True,
moe_expert_cache_size=8, # LFRU cache of 8 hot experts per layer
kernel_config={'moe_backend': 'triton'},
gpu_memory_utilization=0.95,
)
out = llm.generate(['What is 2+3?'], SamplingParams(max_tokens=200))
print(out[0].outputs[0].text)
| Cache | Model VRAM | Speed | Target GPU |
|---|---|---|---|
| 8 | ~7.6 GB | ~16 tok/s | RTX 4090 (24 GB) |
| 16 | ~11 GB | ~20 tok/s | RTX 4090 (24 GB) |
| 32 | ~19 GB | ~25 tok/s | RTX 4090 (24 GB) |
| 64 | ~34 GB | ~35 tok/s | A6000 (48 GB) |
This repo is the HLWQ Q5 quantized version of Nemotron-Cascade-2-30B-A3B:
codes / ct / norms triplets for quantized Linear + Mamba in/out projections)For GPUs with 64+ GB VRAM where expert offload is unnecessary, you can dequantize the HLWQ codes to BF16 and serve them directly:
# Dequant HLWQ Q5 codes → BF16 safetensors
pip install polarengine-vllm
polarquant-convert caiovicentino1/Nemotron-Cascade-2-30B-A3B-HLWQ-Q5 /tmp/nemotron-bf16
# Then serve with mainline vLLM
vllm serve /tmp/nemotron-bf16 --trust-remote-code --dtype bfloat16
This produces a ~60 GB BF16 checkpoint that fits single A100 80 GB or H100 80 GB.
HLWQ Q5 = Walsh-Hadamard rotation + Lloyd-Max 5-bit scalar quantization per 128-block, with Mamba-specific adaptations:
Per-weight compression: ~5 bits + per-block fp16 norm = ~5.125 bits/value. Cosine similarity vs BF16: >0.997 on sampled probes.
HLWQ replaces the author's earlier "PolarQuant" branding to disambiguate from Han et al. 2025 (arXiv:2502.02617), a distinct KV-cache quantization method published under the same name.
The two techniques address different components (weights vs KV cache) and are unrelated.
Internally, the quant_method field in config.json remains "polarengine" — that is the wire-format string recognized by transformers and vLLM loaders. Brand is HLWQ; wire format is polarengine.
@misc{vicentino2026hlwq,
title = {Hadamard-Lloyd Weight Quantization (HLWQ): Near-Lossless 5-bit PTQ for LLMs via Walsh-Hadamard Rotation and Lloyd-Max Scalar Quantization},
author = {Vicentino, Caio},
year = {2026},
eprint = {2603.29078},
archivePrefix = {arXiv},
note = {Formerly titled "PolarQuant"; v2 retitle pending to avoid collision with Han et al. 2025.}
}
nvidia/Nemotron-Cascade-2-30B-A3B — 30B hybrid Mamba + MoEBuilt on NVIDIA's Nemotron-Cascade-2-30B-A3B hybrid Mamba + MoE architecture. Thanks to the vLLM team for the expert offload review (PR #37190 in progress) and to Elnur Abdullaev (e1n00r) for driving the upstream implementation.
Base model
nvidia/Nemotron-Cascade-2-30B-A3B